(번역) CRDT에 대한 인터랙티브 입문

원문: https://jakelazaroff.com/words/an-interactive-intro-to-crdts/
CRDT에 대해 들어 본 적이 있고, 무엇인지 궁금한 적이 있나요? 알아보긴 했지만 학술 논문과 수학 전문 용어의 벽에 부딪혔을 수도 있습니다. 저도 Recurse Center 배치를 시작하기 전에 그랬습니다. 하지만 지난 한 달 동안 연구하고 코드를 작성하는 과정에서 몇 가지 간단한 것만으로도 많은 것을 만들 수 있다는 것을 알게 되었습니다!
2부로 구성된 시리즈를 통해 CRDT가 무엇인지 알아보겠습니다. 그런 다음 원시 CRDT를 작성하고 이를 더 복잡한 데이터 구조로 구성한 뒤, 마지막으로 배운 내용을 사용하여 협업 가능한 픽셀 아트 편집기를 구축해 보겠습니다. 이 모든 것은 CRDT에 대한 사전 지식이 없어도 타입스크립트에 대한 기초 지식만 있으면 가능합니다.
우리가 앞으로 작성할 결과물은 다음과 같습니다.

마우스를 클릭하고 드래그해 그림을 그릴 수 있습니다. 왼쪽 하단의 색상 입력을 사용하여 페인트 색상을 변경할 수도 있습니다. 또한, 두 캔버스 중 하나에 그림을 그리면 마치 동일한 그림에서 협업하는 것처럼 변경 내용이 다른 캔버스에 표시됩니다.
네트워크 버튼을 클릭하면 변경 사항이 다른 캔버스에 도달하지 못하도록 방지됩니다(다시 “온라인” 상태가 되면 동기화됨). 지연 슬라이더는 한 캔버스의 변경 사항이 다른 캔버스에 표시되기 전에 지연 시간을 추가합니다.
다음 게시물에서 이를 구축할 것입니다. 먼저 우리는 CRDT에 대해 알아볼 필요가 있습니다!
CRDT가 뭘까요?
자, 제일 처음부터 시작해 보죠. CRDT는 “Conflict-free Replicated Data Type”(충돌 없는 복제된 데이터 타입)의 약자입니다. 긴 약어이지만 개념은 그렇게 복잡하지 않습니다. 서로 다른 컴퓨터(피어)에 저장할 수 있는 데이터 구조의 한 타입입니다. 각 피어는 다른 피어를 확인하기 위한 네트워크 요청 없이도 자체 상태를 즉시 업데이트할 수 있습니다. 피어는 서로 다른 시간에 서로 다른 상태를 가질 수 있지만 최종적으로 하나의 합의된 상태로 수렴하게 됩니다. 따라서 중앙 서버에서 변경 사항을 동기화할 필요 없이 Google Docs 및 Figma와 같은 풍부한 협업 앱을 구축하는 데 CRDT를 유용하게 사용할 수 있습니다.
CRDT에는 크게 두 가지 타입이 있습니다. 상태 기반 CRDT와 작업 기반 CRDT입니다.(1) 상태 기반 CRDT는 피어 간에 전체 상태를 전송하고, 모든 상태를 병합하여 새 상태를 얻습니다. 작업 기반 CRDT는 사용자가 수행하는 작업만 전송하고 이를 사용하여 새 상태를 계산합니다.
(1): CRDT는 CvRDT(Cv는 convergent의 약자)와 CmRDT(Cm은 commutative의 약자)로도 알려져 있지만, 개인적으로는 상태 기반 CRDT와 작업 기반 CRDT가 더 선호되는 용어라고 생각합니다.
이런 부분이 작업 기반 CRDT가 훨씬 더 좋게 보일 수 있습니다. 예를 들어, 사용자가 목록의 한 항목을 업데이트하면 작업 기반 CRDT는 해당 업데이트에 대한 설명만 전송할 수 있지만 상태 기반 CRDT는 전체 목록을 전송해야 합니다! 그러나 작업 기반 CRDT는 통신 채널에 제약을 가한다는 단점이 있습니다. 메시지는 각 피어에게 정확히 한 번, 인과 순서에 맞게 전달되어야 합니다.(2)
(2): 또한, 피어가 서로 주고받아야 하는 상태의 하위 집합을 협상할 수 있는 델타 CRDT 또는 하이브리드 CRDT가 있습니다. 이는 작업 기반 CRDT와 상태 기반 CRDT를 혼합한 한 예입니다. 그러나 근본적인 대가(trade-off)는 여전히 남아 있습니다. 피어 간에 보내는 데이터가 적을수록 통신에 대한 제약이 더 많다는 것입니다.
이 글은 상태 기반 CRDT에 대해서만 초점을 맞출 것입니다. 간결하게 작성하기 위해 이제부터 “CRDT”라고만 작성할 것이며, 이는 상태 기반 CRDT를 구체적으로 언급하고 있음을 참고해 주세요.
지금까지 CRDT가 하는 일에 관해 이야기했습니다. 근데, CRDT는 무엇일까요? 구체적으로 설명하자면, CRDT는 이 인터페이스를 구현하는 모든 데이터 구조입니다. (3)
(3): 기술적으로 CRDT는 아래 설명된 병합 규칙을 따르는 모든 것이 될 수 있습니다. CRDT는 실무적인 정의이며, 실제로 객체 지향 언어로 구현하면 다음과 같습니다.
interface CRDT<T, S> {
value: T;
state: S;
merge(state: S): void;
}즉, CRDT는 최소 세 가지를 포함합니다.
- 값(value),
T. 나머지 프로그램이 중요하게 여기는 부분입니다. CRDT의 핵심은 피어 간에 값을 안정적으로 동기화하는 것입니다. - 상태(state),
S. 피어가 동일한 값에 동의하는 데 필요한 메타데이터입니다. 다른 피어를 업데이트하려면 전체 상태가 직렬화되어 피어에 전송됩니다. - 병합 함수(merge function). 이 함수는 일부 상태(아마 다른 피어에서 받은 상태)를 가져와 로컬 상태와 병합하는 함수입니다.
병합 함수는 모든 피어가 동일한 결과에 도달하도록 보장하기 위해 아래 세 가지 속성을 만족해야 합니다(상태 A를 상태 B에 병합하는 것을 A ∨ B로 표시하겠습니다.).
- 가환성(commutativity): 상태는 어떤 순서로든 병합할 수 있습니다.
A ∨ B = B ∨ A. 앨리스와 밥이 상태를 교환하면, 각각 상대방의 상태를 자신의 상태에 병합해 동일한 결과에 도달할 수 있습니다. - 결합성(associativity): 세 개(또는 이상)의 상태를 병합할 때 먼저 병합하는 상태가 중요하지 않습니다.
(A ∨ B) ∨ C = A ∨ (B ∨ C). 앨리스가 밥과 캐럴로부터 모두 상태를 받으면 어떤 순서든 자신의 상태에 병합할 수 있으며 결과는 동일합니다.(4) - 항등성(idempotence): 상태를 자체와 병합해도 상태가 변경되지 않습니다.
A ∨ A = A. 앨리스가 자신의 상태를 자신과 병합하면 결과는 시작한 상태와 동일합니다.
(4): 가환성과 결합성은 동일하게 들릴 수 있으며, 실제로 대부분의 가환 연산은 결합적입니다. 그러나 한쪽 또는 다른 쪽에만 적용되는 몇 가지 수학 연산이 있습니다. 예를 들어, 행렬 곱셈은 결합적이지만 가환적이지 않습니다. 그리고 놀랍게도 부동 소수점 연산(즉, 자바스크립트의 모든 수학 연산자)은 가환적이지만 결합적이지 않습니다!
병합 함수가 이런 속성을 모두 갖는 것을 수학적으로 증명하는 것은 어려울 수 있습니다. 하지만 다행히도 우리는 그럴 필요가 없습니다! 대신 누군가가 이런 사실을 증명했다는 사실에 기대 이미 존재하는 CRDT를 결합하면 됩니다.
이미 존재하는 CRDT 중 한 가지에 대해 먼저 알아보겠습니다!
Last Write Wins Register
레지스터는 단일 값을 보유하는 CRDT입니다. 레지스터는 몇 가지 종류가 있지만 가장 간단한 것은 Last Write Wins Register(LWW Register)입니다.
LWW Register는 이름에서 알 수 있듯이 단순히 값이 업데이트될 때마다 증가하는 정수로 표현되는 타임스탬프를 사용하여 가장 최근에 작성된 값으로 현재 값을 덮어씁니다.(5) 알고리즘은 다음과 같습니다.
(5): 왜 실제 시간을 사용하지 않느냐고 반문할 수도 있습니다. 안타깝게도 두 컴퓨터 간의 시간을 정확하게 동기화하는 것은 매우 어려운 문제입니다. 이처럼 증분(incremental) 정수를 사용하는 것은 논리적 시계의 간단한 버전 중 하나로, '벽시계'가 아닌 서로를 기준으로 이벤트 순서를 캡처합니다.
- 수신된 타임스탬프가 로컬 타임스탬프보다 작으면 레지스터의 상태가 변경되지 않습니다.
- 수신된 타임스탬프가 로컬 타임스탬프보다 크면 레지스터는 로컬 값을 수신된 값으로 덮어씁니다. 또한, 수신된 타임스탬프와 마지막으로 값을 작성한 피어의 고유 식별자(피어 ID)를 저장합니다.
- 로컬 피어 ID와 수신 상태의 피어 ID를 비교하여 연결이 끊어집니다.
아래 예제에서 직접 시도해 보세요.

LWW Register가 어떻게 작동하는지 이해했나요? 아래는 몇 가지 시도해 볼 법한 구체적인 시나리오입니다.
- 네트워크를 끄고 Bob에게 몇 가지 업데이트를 하고 다시 켜보세요. Alice에서 업데이트를 보내면 타임스탬프가 Bob의 타임스탬프를 초과할 때까지 거부됩니다.
- 동일한 설정을 수행하지만, 네트워크를 다시 켜고 Bob에서 Alice로 업데이트를 보내면, 타임스탬프가 이제 동기화되고 Alice가 Bob에게 다시 작성할 수 있습니다!
- 지연 시간을 늘리고 두 피어에서 동시에 업데이트를 보내볼까요? Alice는 Bob의 업데이트를 수락하지만 Bob은 Alice의 업데이트를 거부합니다. Bob의 피어 ID가 더 크기 때문에 타임스탬프 타이를 끊습니다.
아래는 LWW Register 코드입니다.
class LWWRegister<T> {
readonly id: string;
state: [peer: string, timestamp: number, value: T];
get value() {
return this.state[2];
}
constructor(id: string, state: [string, number, T]) {
this.id = id;
this.state = state;
}
set(value: T) {
// 로컬 ID로 피어 ID 설정, 로컬 타임스탬프를 1 증가시키고 값 설정
this.state = [this.id, this.state[1] + 1, value];
}
merge(state: [peer: string, timestamp: number, value: T]) {
const [remotePeer, remoteTimestamp] = state;
const [localPeer, localTimestamp] = this.state;
// 로컬 타임스탬프가 원격 타임스탬프보다 크면 들어오는 값을 무시
if (localTimestamp > remoteTimestamp) return;
// 타임스탬프는 동일하지만 로컬 피어 ID가 원격 피어 ID보다 크면 들어오는 값을 무시
if (localTimestamp === remoteTimestamp && localPeer > remotePeer) return;
// 그렇지 않으면 로컬 상태를 원격 상태로 덮어쓰기
this.state = state;
}
}LWW Register가 CRDT 인터페이스와 어떻게 매치되는지 살펴보죠.
state는 레지스터에 마지막으로 작성한 피어 ID, 마지막 작성의 타임스탬프 및 레지스터에 저장된 값의 튜플입니다.value은 단순히 상태 튜플의 마지막 요소입니다.merge은 위에서 설명한 알고리즘을 구현하는 메서드입니다.
LWW Register는 set이라는 메서드가 하나 더 있습니다. 이 메서드는 레지스터의 값을 로컬로 설정하는 목적의 함수입니다. 또한 로컬 메타데이터를 업데이트하여 로컬 피어 ID를 마지막 작성자로 기록하고 로컬 타임스탬프를 1 증가시킵니다.
그게 전부입니다! 간단해 보이지만 평범한 LWW Register는 실제 애플리케이션을 만들 수 있는 강력한 빌딩 블록입니다.
Last Write Wins Map
대부분의 프로그램은 하나 이상의 값을 포함하므로, LWW Register보다 더 복잡한 CRDT가 필요합니다. 이제 살펴볼 CRDT는 Last Write Wins Map(또는 LWW Map)입니다.
먼저 두 가지 타입을 정의해 보겠습니다. 첫번째 우리 값 타입은 다음과 같습니다.
type Value<T> = {
[key: string]: T;
};각 개별 맵 값의 타입이 T인 경우 전체 LWW Map의 값은 문자열 키와 T 값의 매핑입니다.
LWW Map의 상태 타입은 다음과 같이 정의됩니다.
type State<T> = {
[key: string]: LWWRegister<T | null>["state"];
};트릭이 보이나요? LWW Map은 애플리케이션 관점에서 보면 일반 값을 보관하는 것처럼 보이지만 실제로는 LWW Register를 보관합니다. 전체 상태를 살펴보면 각 키의 상태는 해당 키의 LWW Register 상태입니다.(7)
(7): 값 타입이T인 경우 state 타입이T | null인 이유는 잠시 후 설명하겠습니다.
이 부분은 중요하니 잠시 멈춰 보겠습니다. 합성을 통해 원시 CRDT를 좀 더 복잡한 것으로 결합할 수 있습니다. 병합할 때 부모는 들어오는 상태 조각을 적절한 자식의 병합 함수에 전달하기만 하면 됩니다. 이 과정은 원하는 횟수만큼 중첩할 수 있으며, 각 복잡한 CRDT는 점점 더 작은 상태 조각 수준으로 전달하여 마침내 실제 병합을 수행하는 기본 CRDT에 도달할 때까지 이어집니다.
이러한 관점에서 LWW Map 병합 함수는 간단합니다. 각 키를 순회하고 해당 키의 들어오는 상태를 해당 LWW Register에 병합하도록 전달합니다. 아래 플레이그라운드에서 시도해 볼까요?

일어나는 일을 추적하기가 어려우므로 각 키에 대한 상태를 분할해 보겠습니다. 그러나 이것은 단지 시각화 보조 도구일 뿐이며 전체 상태는 여전히 단일 단위로 전송된다는 점을 유의하세요.
지연 시간을 늘린 다음 각 피어에서 다른 키를 업데이트해 보세요. 각 피어가 타임스탬프가 더 높은 업데이트된 값은 수락하고 타임스탬프가 더 낮은 값은 거부하는 것을 볼 수 있습니다.

전체 LWW Map 클래스는 다소 복잡하므로 각 속성을 하나씩 살펴 보겠습니다. 여기서부터 시작해 보죠.
class LWWMap<T> {
readonly id = "";
#data = new Map<string, LWWRegister<T | null>>();
constructor(id: string, state: State<T>) {
this.id = id;
// 초기 상태의 각 키에 대해 새 레지스터를 생성합니다.
for (const [key, register] of Object.entries(state)) {
this.#data.set(key, new LWWRegister(this.id, register));
}
}
}#data는 LWW Register 인스턴스에 대한 키 맵을 보유한 private 프로퍼티입니다. 기존 상태로 LWW Map을 인스턴스화하려면 상태를 반복하고 각 LWW Register를 인스턴스화해야 합니다.
CRDT에는 value, state 및 merge 세 가지 속성이 필요합니다. 먼저 value에 대해 살펴보죠.
get value() {
const value: Value<T> = {};
// 각 값이 해당 키의 레지스터 값으로 설정된 객체를 구축합니다.
for (const [key, register] of this.#data.entries()) {
if (register.value !== null) value[key] = register.value;
}
return value;
}키를 반복하고 각 레지스터의 값을 가져오는 게터입니다. 앱의 나머지 부분은 단지 일반적인 맵으로 보입니다!
이제 state를 살펴보겠습니다.
get state() {
const state: State<T> = {};
// 각 값이 해당 키에서 레지스터의 전체 상태로 설정된 객체를 구축합니다.
for (const [key, register] of this.#data.entries()) {
if (register) state[key] = register.state;
}
return state;
}값과 유사하게, 이것은 각 레지스터의 상태에서 맵을 구축하는 게터입니다.
여기에는 명확한 경향이 있습니다. #data의 키를 반복하고 해당 키에 저장된 레지스터에 작업을 전달합니다. merge도 같은 방식으로 작동할 것으로 생각할 수 있지만, 조금 더 복잡합니다.
merge(state: State<T>) {
// 각 키의 레지스터를 해당 키의 수신 상태와 재귀적으로 병합합니다.
for (const [key, remote] of Object.entries(state)) {
const local = this.#data.get(key);
// 레지스터가 이미 존재하면 들어오는 상태와 병합합니다.
if (local) local.merge(remote);
// 그렇지 않으면, 들어오는 상태와 함께 새로운 `LWWRegister`를 인스턴스화합니다.
else this.#data.set(key, new LWWRegister(this.id, remote));
}
}먼저 로컬 #data가 아닌 들어오는 state 매개변수를 반복합니다. 그 이유는 들어오는 상태에 #data에 있는 키가 누락된 경우 해당 키를 건드릴 필요가 없다는 것을 알 수 있기 때문입니다. (8)
(8): 다른 피어가 맵에서 키를 삭제한 경우 로컬 맵에서도 키를 제거해야 하지 않을까요? state가T | null을 보관하는 것과 같은 이유입니다. 이제 이해되시나요?
들어오는 상태의 각 키에 대해 해당 키의 로컬 레지스터를 가져옵니다. 이를 찾으면 피어가 우리가 이미 알고 있는 기존 키를 업데이트하는 것이므로 해당 키에서 들어오는 상태와 해당 레지스터의 merge 메서드를 호출해 병합합니다. 그렇지 않으면 피어가 맵에 새 키를 추가한 것이므로 키에서 들어오는 상태를 사용하여 새 LWW Register를 인스턴스화합니다.
CRDT 메서드 외에도 맵에서 더 일반적으로 사용되는 메서드(set, get, delete 및 has)를 구현해야 합니다.
먼저 set부터 시작해 보죠.
set(key: string, value: T) {
// 주어진 키에서 레지스터를 가져옵니다
const register = this.#data.get(key);
// 레지스터가 이미 존재하면 값을 설정합니다.
if (register) register.set(value);
// 그렇지 않으면 값으로 새 `LWWRegister`를 인스턴스화합니다.
else this.#data.set(key, new LWWRegister(this.id, [this.id, 1, value]));
}merge 메서드와 마찬가지로 레지스터의 set을 호출해 기존 키를 업데이트하거나 새 LWW Register를 인스턴스화하여 새 키를 추가합니다. 초기 상태는 로컬 피어 ID, 타임스탬프 1, 설정에 전달된 값을 사용합니다.
get은 훨씬 더 간단합니다.
get(key: string) {
return this.#data.get(key)?.value ?? undefined;
}로컬 맵에서 레지스터를 가져오고 값이 있으면 반환합니다.
왜 undefined로 병합할까요? 각 레지스터는 T | null을 보관하기 때문입니다. 그리고 delete 메서드 설명까지 마친다면, 이제 왜 그런지 설명할 준비가 마무리됩니다.
delete(key: string) {
// register가 존재하는 경우 null로 처리
this.#data.get(key)?.set(null);
}맵에서 키를 완전히 제거하는 대신 레지스터 값을 null로 설정합니다. 메타데이터는 계속 유지되므로 아직 키가 없는 상태에서 삭제되었는지 구분할 수 있습니다. 이를 **툼스톤(tombstone)**이라고 하는데, 과거 CRDT의 유산입니다.
툼스톤을 남기지 않고 키를 맵에서 완전히 삭제하면 어떤 일이 발생할지 생각해 보죠. 아래에 피어가 키를 추가할 수 있지만 삭제할 수 없는 플레이그라운드를 만들어 봤습니다. 피어가 키를 삭제하도록 하는 방법을 알아낼 수 있나요?
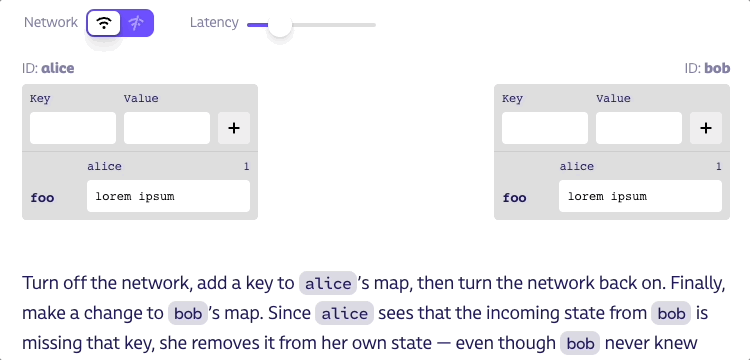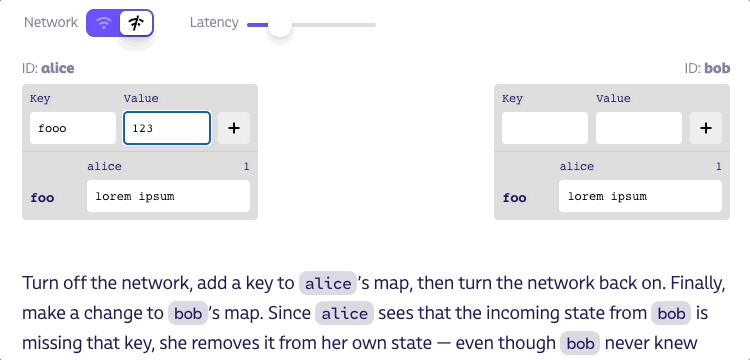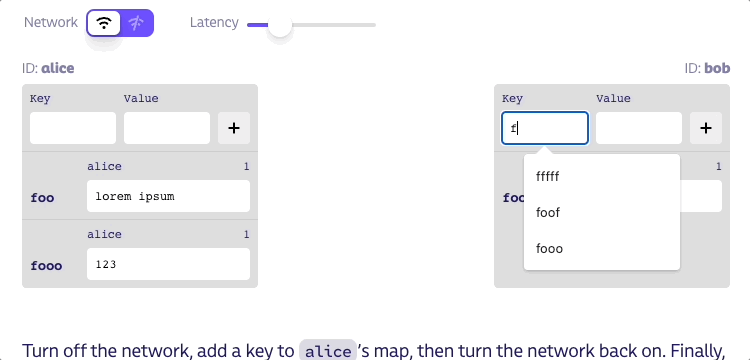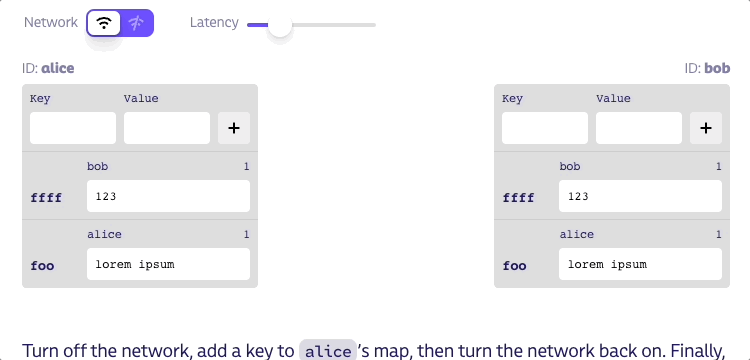
네트워크를 끄고 alice의 맵에 키를 추가한 다음 네트워크를 다시 켭니다. 마지막으로 bob의 맵을 변경합니다. alice는 bob으로부터 들어오는 상태에 해당 키가 없다는 것을 알게 되므로 bob이 처음부터 해당 키에 대해 알지 못했더라도 자신의 상태에서 해당 키를 제거합니다. 이런 동작은 말이 안 됩니다!
아래 정확한 동작이 있는 플레이그라운드가 있습니다. 키가 삭제될 때 어떤 일이 발생하는지도 볼 수 있습니다.

삭제된 키를 맵에서 제거하지 않는다는 점을 유의하세요. 이것은 CRDT의 한 가지 단점인데, 정보를 추가할 수 있지만 제거할 수는 없습니다. 앱의 관점에서 키가 완전히 삭제되었더라도 기본 상태에는 키가 있었다는 것이 여전히 기록됩니다. 기술 용어로 CRDT는 단조 증가(monotonically increasing) 데이터 구조라고 합니다. (9)
(9): 이 단점을 완화하는 몇 가지 있지만 본문의 범위를 벗어납니다. 하나는 "가비지 콜렉팅"입니다. CRDT에서 툼스톤을 제거하여 툼스톤이 제거되기 전에 수행된 변경 사항이 있는 상태를 병합하는 것을 방지합니다. 다른 하나는 데이터를 인코딩하기 위한 효율적인 형식을 만드는 것입니다. 이러한 방법을 결합할 수도 있습니다. 연구에 따르면 이는 "일반" 데이터에 비해 50% 정도의 오버헤드가 발생할 수 있습니다.
마지막 LWW Map 메서드는 has입니다. 이 메서드는 지정된 키가 맵에 포함되어 있는지를 나타내는 불린 값을 반환합니다.
has(key: string) {
// 레지스터가 존재하지 않거나 값이 null이면 맵에 키가 포함되지 않습니다.
return this.#data.get(key)?.value !== null;
}맵에 지정된 키에 레지스터가 있지만 레지스터에 null이 포함된 경우 맵에 해당 키가 없는 것으로 간주합니다.
그럼 이제 LWW Map 코드 전체를 살펴보죠.
class LWWMap<T> {
readonly id: string;
#data = new Map<string, LWWRegister<T | null>>();
constructor(id: string, state: State<T>) {
this.id = id;
// 초기 상태의 각 키에 대해 새 레지스터를 생성합니다.
for (const [key, register] of Object.entries(state)) {
this.#data.set(key, new LWWRegister(this.id, register));
}
}
get value() {
const value: Value<T> = {};
// 각 값이 해당 키의 레지스터 값으로 설정된 객체를 구축합니다.
for (const [key, register] of this.#data.entries()) {
if (register.value !== null) value[key] = register.value;
}
return value;
}
get state() {
const state: State<T> = {};
// 각 값이 해당 키에서 레지스터의 전체 상태로 설정된 객체를 구축합니다.
for (const [key, register] of this.#data.entries()) {
if (register) state[key] = register.state;
}
return state;
}
has(key: string) {
return this.#data.get(key)?.value !== null;
}
get(key: string) {
return this.#data.get(key)?.value;
}
set(key: string, value: T) {
// 주어진 키에서 레지스터를 가져옵니다
const register = this.#data.get(key);
// 레지스터가 이미 존재하면 값을 설정합니다.
if (register) register.set(value);
// 그렇지 않으면 값으로 새 `LWWRegister`를 인스턴스화합니다.
else this.#data.set(key, new LWWRegister(this.id, [this.id, 1, value]));
}
delete(key: string) {
// register가 존재하는 경우 null로 처리
this.#data.get(key)?.set(null);
}
merge(state: State<T>) {
// 각 키의 레지스터를 해당 키의 수신 상태와 재귀적으로 병합합니다.
for (const [key, remote] of Object.entries(state)) {
const local = this.#data.get(key);
// 레지스터가 이미 존재하면 들어오는 상태와 병합합니다.
if (local) local.merge(remote);
// 그렇지 않으면, 들어오는 상태와 함께 새로운 `LWWRegister`를 인스턴스화합니다.
else this.#data.set(key, new LWWRegister(this.id, remote));
}
}
}다음 단계
지금 이 글을 읽고 있다면 이 글은 게시되었지만 다음 글은 게시되지 않았습니다. 다음 글이 준비되면 알림을 받으려면 RSS 피드를 구독하세요!